Gaurav Kumar Nayak, Konda Reddy Mopuri, Saksham Jain, Anirban Chakraborty
IEEE Trans. on PAMI, 2021
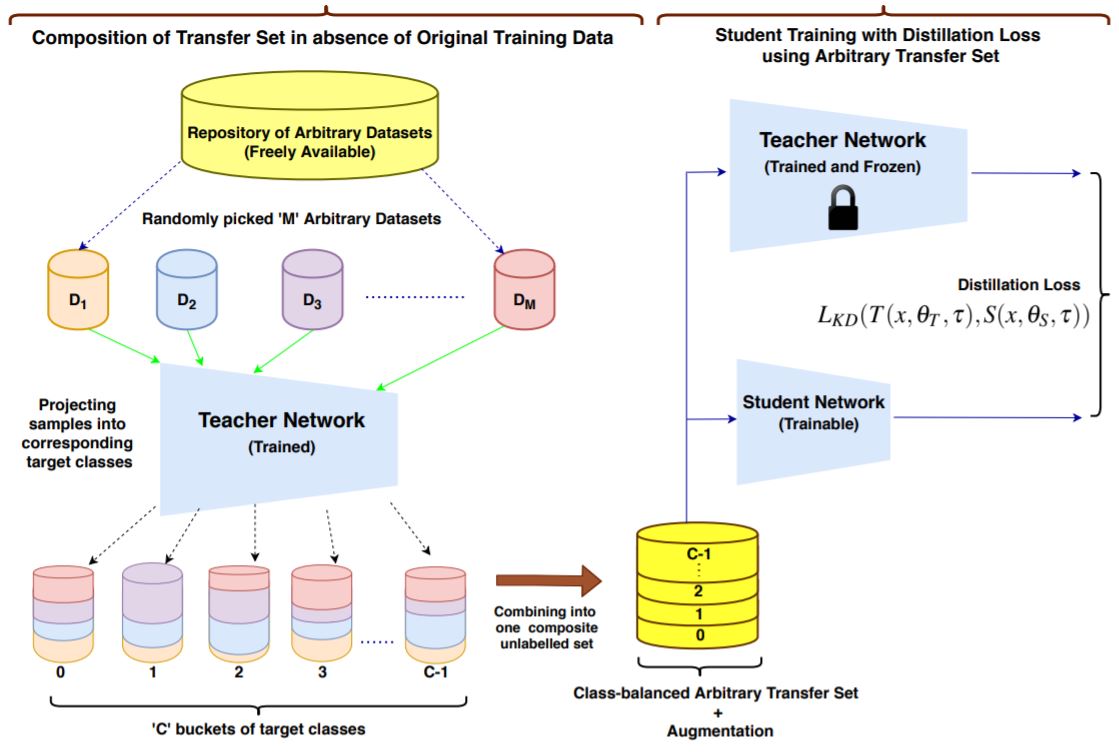
Pretrained deep models hold their learnt knowledge in the form of the model parameters. These parameters act as memory for the trained models and help them generalize well on unseen data. However, in the absence of training data, the utility of a trained model is merely limited to either inference or better initialization towards a target task. In this paper, we go further and extract synthetic data by leveraging the learnt model parameters. We dub them "Data Impressions", which act as proxy to the training data and can be used to realize a variety of tasks. These are useful in scenarios where only the pretrained models are available and the training data is not shared (e.g., due to privacy or sensitivity concerns). We show the applicability of data impressions in solving several computer vision tasks such as unsupervised domain adaptation, continual learning as well as knowledge distillation.Extensive experiments performed on several benchmark datasets demonstrate competitive performance achieved using data impressions in absence of the original training data.